 Querydsl (JPA) 에서 Cross Join 발생할 경우
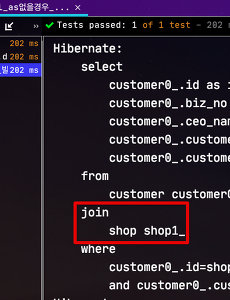
JPA 기반의 환경에서 Querydsl를 사용하다보면 @OneToOne 관계에서 Join 쿼리 작성시 주의하지 않으면 Cross Join이 발생할 수 있습니다. CrossJoin 이란 집합에서 나올 수 있는 모든 경우를 이야기 합니다. 예로 A 집합 {a, b}, B 집합 {1,2,3}이며 이들의 CrossJoin은 AxB로 다음과 같습니다. {(a, 1), (a, 2), (a, 3), (b, 1), (b, 2), (b, 3)} 당연히 일반적인 Join보다 성능상 이슈가 발생하게 됩니다. 이번 시간에는 어떤 경우에 이런 Cross Join이 발생하는지, 어떻게 해결할 수 있는지 확인해보겠습니다. 모든 코드는 Github에 있습니다. 1. 테스트 환경 테스트 환경은 다음과 같습니다. Spring Boot ..
2020. 11. 16.
Querydsl (JPA) 에서 Cross Join 발생할 경우
JPA 기반의 환경에서 Querydsl를 사용하다보면 @OneToOne 관계에서 Join 쿼리 작성시 주의하지 않으면 Cross Join이 발생할 수 있습니다. CrossJoin 이란 집합에서 나올 수 있는 모든 경우를 이야기 합니다. 예로 A 집합 {a, b}, B 집합 {1,2,3}이며 이들의 CrossJoin은 AxB로 다음과 같습니다. {(a, 1), (a, 2), (a, 3), (b, 1), (b, 2), (b, 3)} 당연히 일반적인 Join보다 성능상 이슈가 발생하게 됩니다. 이번 시간에는 어떤 경우에 이런 Cross Join이 발생하는지, 어떻게 해결할 수 있는지 확인해보겠습니다. 모든 코드는 Github에 있습니다. 1. 테스트 환경 테스트 환경은 다음과 같습니다. Spring Boot ..
2020. 11. 16.





