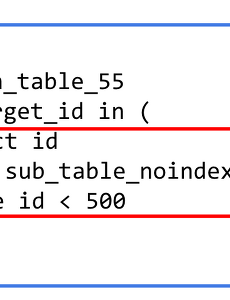
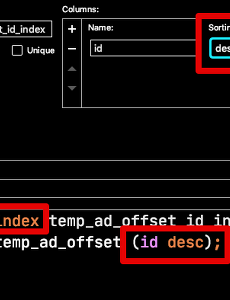
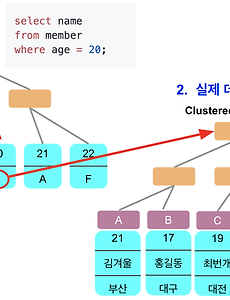
Performance20 MySQL where in (서브쿼리) vs 조인 조회 성능 비교 (5.5 vs 5.6) MySQL 5.5에서 5.6으로 업데이트가 되면서 서브쿼리(Subquery) 성능 개선이 많이 이루어졌습니다. 이번 시간에는 MySQL 2개의 버전 (5.5, 5.6) 에서 서브쿼리를 통한 조회 (Select)와 Join에서의 조회간의 성능 차이를 비교해보겠습니다. MySQL의 정석과도 같은 Real MySQL 책이 MySQL 5.5 버전을 기준으로 하다보니 5.6 변경분에 대해서 별도로 포스팅하게 되었습니다. 0. 테스트 환경 테스트용 테이블은 2개를 만들었습니다. 메인 테이블 100만건 서브 테이블1 (인덱스 O) 1000건 서브 테이블2 (인덱스 X) 1000건 DDL 쿼리는 다음과 같습니다. 메인 테이블 -- 업데이트 대상 테이블 create table main_table ( id int not .. 2020. 8. 27. Querydsl Select 필드로 Entity 사용시 주의 사항 JPA 기반의 애플리케이션 개발에서 복잡한 조회가 필요할때는 Querydsl을 많이 사용합니다.아무래도 Querydsl로 추상화된 상태에서 쿼리를 작성하다보면 실제 어떻게 쿼리가 발생하는지 확인하지 않고 개발할때가 많습니다. 이를테면 쿼리 한번으로 해결하기 위해 select 필드에 Entity를 그대로 선언하는 경우가 바로 그런 경우인데요.(아래와 같은 쿼리일때입니다.) // customer는 Customer queryFactory .select(Projections.fields(EntityB.class, ... EntityA.EntityC) // EntityA의 EntityC 를 바로 선언 ) .from(EntityA) .where(..조건문..) .fetch() 위와 같이 쿼리를 작성하게 되면 Ent.. 2020. 8. 13. JPA exists 쿼리 성능 개선 Spring Data Jpa를 사용하다보면 해당 조건의 데이터가 존재하는지 확인 하기 위해 exists 쿼리가 필요할때가 많습니다. 간단한 쿼리의 경우엔 아래와 같이 메소드로 쿼리를 만들어서 사용하는데요. boolean existsByName(String name); 조금이라도 복잡하게 되면 메소드명으로만 쿼리를 표현하기는 어렵습니다. 조건문이 3개 이상이거나, 필드명이 너무 길거나 조건문 자체가 복잡하는 등등 그래서 이런 경우엔 보통 @Query 를 사용하는데요. 다만 이럴 경우 JPQL에서 select의 exists 를 지원하지 않습니다. (select exists 문법) 단, where의 exists는 지원합니다. 그래서 exists 를 우회하기 위해 아래와 같이 count 쿼리를 사용합니다. @Q.. 2020. 8. 6. 2. 커버링 인덱스 (WHERE + ORDER BY / GROUP BY + ORDER BY ) 지난 시간에 이어 이번엔 ORDER BY에 대해 알아보겠습니다. 2-1. WHERE + ORDER BY 일반적으로 ORDER BY 의 인덱스 사용 방식은 GROUP BY와 유사합니다만, 한가지 차이점이 있습니다. 바로 정렬 기준입니다. MySQL에서는 인덱스 생성시 컬럼 마다 asc/desc 를 정할수 있는것 처럼 보입니다. (젯브레인사의 DataGrip으로 인덱스 생성시 가능한 것처럼 보입니다만… 안됩니다.) 하지만 8.0 이전 버전까지는 지원하지 않습니다. 8.0 이전 버전까지는 문법만 지원되고 실제로 Desc 인덱스가 지원되는 것은 아닙니다. 단지 Ascending index 으로 만들어진 인덱스를 앞에서부터 읽을 것인지 (Forward index scan), 뒤에서부터 읽을 것인지 (Backwar.. 2020. 2. 29. Querydsl 에서 Group by 최적화하기 (feat. MySQL) 1. MySQL에선 Group by를 하면 정렬도 수행된다고? 일반적으로 MySQL 에서 Group By를 실행하면 file sort가 필수로 들어갑니다. 별도의 Order by가 쿼리에 포함되지 않았음에도 file sort가 발생하는 것이죠. Group by 실행시 해당 컬럼들을 기준으로 정렬이 되니 좋아보일수 있겠지만, 의도치 않게 성능 저하가 발생하는 이유가 되기도 합니다. 물론 인덱스에 있는 컬럼들로 Group by를 한다면 큰 문제가 되지 않습니다. 인덱스로 인해서 이미 컬럼들이 정렬된 상태이기 때문입니다. 정렬이 필요 없는 Group by 된 결과가 필요한 경우엔 굳이 정렬할 필요가 없겠죠? 이 문제를 해결하는 방법이 바로 order by null 입니다. 아래와 같이 order by null.. 2020. 2. 21. 1. 커버링 인덱스 (기본 지식 / WHERE / GROUP BY) 일반적으로 인덱스를 설계한다고하면 WHERE절에 대한 인덱스 설계를 이야기하지만 사실 WHERE뿐만 아니라 쿼리 전체에 대해 인덱스 설계가 필요합니다. 인덱스의 전반적인 내용은 이전 포스팅을 참고하시면 좋습니다. 인덱스는 데이터를 효율적으로 찾는 방법이지만, MySQL의 경우 인덱스안에 포함된 데이터를 사용할 수 있으므로 이를 잘 활용한다면 실제 데이터까지 접근할 필요가 전혀 없습니다. 이처럼 쿼리를 충족시키는 데 필요한 모든 데이터를 갖고 있는 인덱스를 커버링 인덱스 (Covering Index 혹은 Covered Index) 라고합니다. 좀 더 쉽게 말씀드리면 SELECT, WHERE, ORDER BY, GROUP BY 등에 사용되는 모든 컬럼이 인덱스의 구성요소인 경우를 얘기합니다. 1-1. 커버링.. 2020. 2. 16. 이전 1 2 3 4 다음